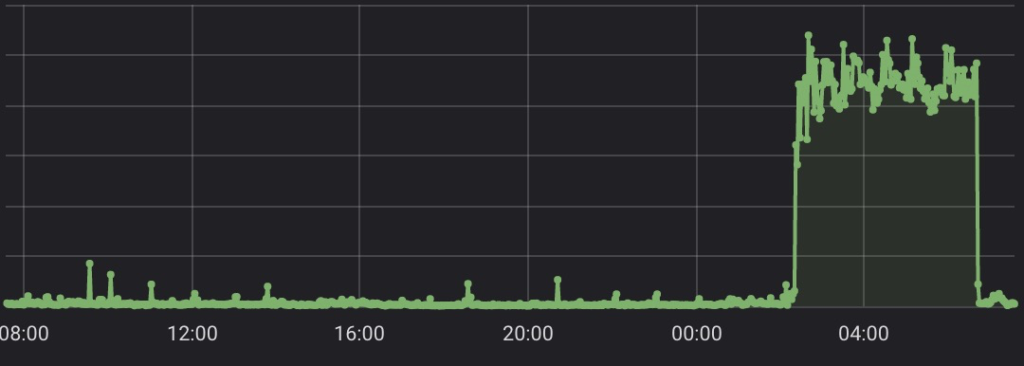
Tech news has recently been full of CVEs related to a popular JVM logging library named Log4J.
Mailsac services do rely on JVM languages, including Java. This extends through the entire stack, custom apps, self-hosted open source software, internal and external, infrastructure, proxies, and scripts.
There is one exception – an instance of the CI server Jenkins which is isolated behind a VPN, and is was never vulnerable according to troubleshooting steps from the Jenkins developers.
Mailsac and Security
The Mailsac Team is small yet mighty, with decades of experience taking security seriously. We follow best practices for infrastructure-as-code, patching, testing, network isolation, backups, restoration, and principle of least access access. Large enterprises including banks and government agencies trust Mailsac for disposable email testing. We provide exceptionally fast and predictable REST and Web Socket APIs with an excellent uptime record.
Mailsac has support for multiple users under the same account, so you can keep disposable email testing private within your company.
It’s free to test email immediately – no payment details required. You can send email to any address @mailsac.com and confirm delivery in seconds without even logging in. Start now at mailsac.com.