The VPS host which handles the Mailsac database servers is having a routing issue, and most of the microservices are unable to contact it. We are in direct communication with the our support rep regarding this issue and expect it to be resolved ASAP. This is a full outage.
Service status can be tracked here: status.mailsac.com
We apologize for the issue and will be working to minimize the likelihood of this happening again.
Timeline (US Pacific)
– 2018-02-06 09:36 Outage noticed by monitoring services
– 2018-02-06 09:37 Troubleshooting and evaluating logs on shared logging server
– 2018-02-06 09:38 Able to ssh into primary database node from office
– 2018-02-06 09:38 Ticket opened with upstream hosting company indicating many geographically distributed services cannot reach the network of the database servers
– 2018-02-06 09:43 Provided several traceroutes for help troubleshooting
– 2018-02-06 09:59 Monitoring indicates the service is back online
– 2018-02-06 10:03 All frontend UI/API servers were rebooted in series to clear a MongoDB error “Topology was destroyed”
– 2018-02-06 10:05 Error notifications seem to all be cleared
– 2018-02-06 10:10 Updated HAProxy error pages to include links to status page and community website
Edit: Concluding Remarks
Mailsac’s database, for caching and data storage, is MongoDB. Without the database, everything grinds to a halt. MongoDB supports configurations for high availability (Replication with Automatic Failover).
Having all nodes of the database hosted in one provider’s network has proven to not be sufficient to prevent outages. In this case, a router within the hosting company’s network failed, which caused none of the MongoDB nodes to be accessible to the networks of the other hosting companies. We will take some time to change that configuration.
Mailsac already has microservice instances across multiple providers and geographic regions, as seen in the system diagram:
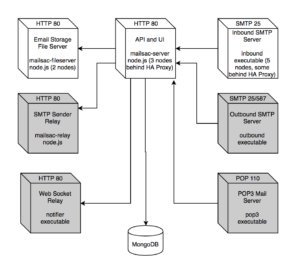
In the event one or two instances went offline, or even an entire region of an upstream host, Mailsac should not go down as long as the database was still accessible to the API. Obviously that was not the case here.
The solution will be to add a Secondary Node and Arbiter in different networks.