The Mailsac Self-Hosted Temporary Email User Interface is available in a GitHub repository. This project provides a self-hosted user interface for viewing disposable email. It uses mailsac.com as the backend email service.
Mailsac.com Limitations
Mailsac already offers disposable email without a need to sign up for an account. What need does this application meet that Mailsac doesn’t already provide?
Mailsac has limitations on what can be viewed without signing up for an account. Only the latest email in a public mailbox can be viewed without signing in. Mail in a private domain cannot be viewed without signing in with an account that has permissions to the private domain.
Use Cases
There are two use cases that customer’s have brought to our attention that Mailsac’s service doesn’t satisfy. Both stem from a requirement to allow users read-only access to an inbox without the requirement of creating a Mailsac account.
Class Room Use Case
An instructor may want students, who are young in age and don’t have an email address, to sign up for an account with a web service used in the class. The Mailsac Self-Hosted Temporary Email User Interface application provides a simplified interface for students to view email sent to a private mailsac hosted domain without the need to sign up for a mailsac account or email address.
Acceptance Tester Use Case
As part of the sofware development lifecycle there is a need to have software tested by users. Temporary email has long been beneficial to testing. The Mailsac Self-Hosted Temporary Email User Interface makes this easier. Users can test applications using email addresses in a Mailsac hosted private domain without the need to sign up for a Mailsac account. Furthermore, because the application is self-hosted companies can use a reverse proxy to enforce IP allow lists or put the application behind basic authentication.
Running the Mailsac Self-Hosted Email User Interface
Local
With NodeJS installed this application can be run with the following commands.
npm install && npm run build
MAILSAC_KEY=YOUR_MAILSAC_API_KEY npm run start
You will need to generate a Mailsac API key. To generate or manage API Keys use the API Keys page.
The application is now running and can be accessed via a web browser at http://localhost:3000 .
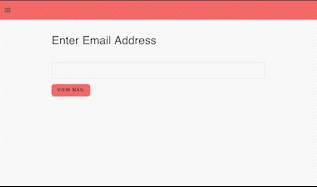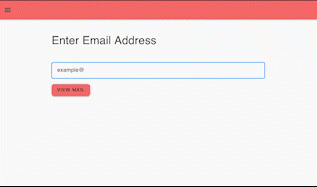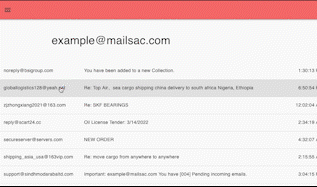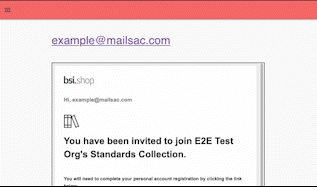
Any public or private Mailsac hosted address the API key has access to can be viewed by entering the email address in the text box and selecting “view mail”.
Domain Option
You can prepopulate the domain by using the NEXT_PUBLIC_MAILSAC_CUSTOM_DOMAIN environment variable.
NEXT_PUBLIC_MAILSAC_CUSTOM_DOMAIN=example.mailsac.com npm run build
MAILSAC_KEY=YOUR_MAILSAC_API_KEY npm run start
Vercel Hosted
Vercel is a platform as a service provider. Their service makes running your own Next.js application easy.
Grant Vercel permissions to read all your repos or choose to grant permission on the forked repo
Import forked repository into Vercel
Configure MAILSAC_KEY environment variable
Deploy application
After a successful deployment you can click on the image of the application to be taken to the live application.
NOTE There is currently no authentication on this application. Anyone with the URL will be able to view emails and domains associated with the Mailsac API key that was used. Operations will be tracked in the Mailsac account in which the API key is associated with.
You are free to deploy this app however you like. Please keep the attribution to Mailsac.
dracula is a high performance, low latency, low resource counting server with auto-expiration.
The Mailsac engineering team recently open sourced our internal throttling service, dracula, under an open source license. Check it out on Github. In the repo we prebuild server and CLI binaries for mac and linux, and provide a client library for Go.
Dracula has performed extremely well in AWS on ARM64 in production for us. It handles thousands of requests per second without noticeable CPU spikes, while maintaining low memory.
In this blog post we’re going to give an overview of why it was necessary, explain how it works, and describe dracula’s limitations.
Why we made it
For the past few years Mailsac tracked throttling in a PostgreSQL unlogged table. By using an unlogged table we didn’t have to worry about lots of disk writes, nor the safety provided by having the write-ahead-log. Throttling records are only kept for a few minutes. We figured if Postgres was rebooting, losing throttling records from the past minutes would be the least of our worries.
In the months leading up to replacing this unlogged table with dracula we began having performance bottlenecks. Mailsac is experiencing fast growth in the past few years. Heavy sustained inbound mail was resulting in big CPU time while Postgres vacuumed the throttling tables. The throttling table started eating too many CPU credits in AWS RDS – credits the we needed for more important stuff like processing emails.
We needed a better throttling solution. One that could independently protect inbound mail processing and REST API services. Postgres was also the primary data store for parsed emails. The Postgres-based solution was a multi-tiered approach to throttling – especially against bad actors – and helped our website and REST API snappy, even when receiving a lot of mail from questionable sources. The throttling layer also caches customer data so we can filter out the paying users from unknown users. Separating this layer from the primary data store would help them scale independently.
Can Redis do it?
So it was time to add a dedicated throttle cache. We reached for Redis, the beloved data structure server.
We were surprised to find our use case – counting quickly-expiring entries – is not something Redis does very well.
Redis can count items in a hash or list. Redis can return keys matching a pattern. Redis can expire keys. But it can’t expire list or hash item entries. And Redis can’t count the number of keys matching a pattern – it can only return those keys which you count yourself.
What we needed Redis to do was count items matching a pattern while also automatically expiring old entries. Since Redis couldn’t do this combination of things, we looked elsewhere.
Other utility services seemed too heavy and full-of-features for our needs. We could have stood up a separate Postgres instance, used MongoDB, Elasticache, or Prometheus. The team has experience running all these services. But the team is also aware that the more features and knobs a service has, the more context is needed to debug it – the more expertise to understand its nuances, the more risk you’ll actually use additional features, and the more risk you’ll be slow responding to issues under heavy load.
All we wanted to do was put some values in a store, have them expired automatically, and frequently count them. We’d need application level logic to do at least some of this, so we made a service for it – dracula. Please check it out and give it a try!
How it works under the hood
Dracula is a server where you can put entries, count the entries, and have the entries automatically expire.
The dracula packet layout is as follows. See protocol.go for the implementation.
Section Description
Command characterPut, Count, Error
space
xxhashpre shared key + id + namespace + data
space
Client Message ID
space
Namespace
space
Entry data
Size
1 byte
1 byte
8 bytes
1 byte
4 bytesunsigned 32 bit integer (Little Endian)
1 byte
64 bytes
1 byte
remaining 1419 bytes
Example
byte(‘P’), ‘C’, ‘E’
byte(‘ ‘)
0x1c330fb2d66be179
byte(‘ ‘)
6 or []byte{6, 0, 0, 0}
byte(‘ ‘)
“Default” or “anything” up to 64 bytes
byte(‘ ‘)
192.169.0.1, or any string up to end of packet
500 byte dracula packet byte order
Here’s roughly how the dracula client-server model works:
The client constructs a 1500 byte packet containing a client-message ID, the namespace, and the value they want to store in the namespace (to be counted later).
A hash of the pre-shared secret + message ID + namespace + entry data is set inside the front part of the message.
A handler is registered under the client message ID.
The bytes are sent over UDP to the dracula server.
Client is listening on a response port.
If no response is received before the message times out, a timeout error is returned and the handler is destroyed. If the response comes after the timeout, it’s ignored.
Server receives packet, decodes it and checks the hash which contains a pre-shared secret.
Server performs the action. There are only two commands – either Put a namespace + entry key, or Count a namespace + entry key.
Server responds to the client using the same command (Put or Count). The entry data is replaced with a 32 bit unsigned integer in the case of a Count command. The hash is computed similarly to before.
Client receives the packed, decodes it and confirms the response hash.
Data structures
Dracula uses a few data structures for storing data.
Namespaces are stored in a hashmap provided by github.com/emirpasic/gods, and we use a simple mutex to sync multithreaded access. Entries in each namespace are stored in wrapped AVL tree from the same repo, which we added garbage collection and thread safety. Each node of the AVL tree has an array of sorted dates.
Here’s another view:
dracula server
Namespaces (hashmap)
Entries (avltree)
sorted dates (go slice / dynamic array of int64)
Server configuration
When using dracula, the client has a different receiving port than the server. By default the dracula server uses port 3509. The server will write responses back to the same UDP port it received messages from on the client.
Messages are stored in a “namespace” which is pretty much just a container for stored values. The namespace is like a top-level key in Redis. The CLI has a default namespace if you don’t provide one. The go client requires choosing a namespace.
Namespaces and entries in namespaces are exact – dracula does not offer any matching on namespaces.
At Mailsac, we use uses the namespaces to separate messages on a per-customer basis, and to separate free traffic. Namespaces are intentionally generic. You could just use one namespace if you like, but performance under load improves if entries are bucketed into namespaces.
Production Performance
Dracula is fast and uses minimal resources by today’s standards.
While we develop it on Intel, and in production we run dracula on Arm64 architecture under Amazon Linux for a significant savings.
In its first months of use, dracula did not spike above 1% CPU usage and 19 MB of RAM, even when handling single-digit-thousands of requests simultaneously.
Tradeoffs
By focusing on a small subset of needs, we designed a service with sharp edges. Some of these may be unexpected features so we want to enumerate what we know.
It only counts
It’s called dracula in an allusion to Count Dracula. There’s no way to list namespaces, keys, nor return stored values. Entries in a namespace can be counted, and the number of namespaces can be counted. That’s it! If we provided features like listing keys or namespace, we would have needed to change the name to List Dracula.
No persistence
Dracula is designed for short-lived ephemeral data. If dracula restarts, nothing is currently saved. This may considered for the future, though. Storing metrics or session data in dracula is an interesting idea. On the other hand, we see no need to reinvent Redis or Prometheus.
Small messages
An entire dracula protocol message is 1500 bytes. If that sounds familiar, it’s because 1500 bytes is the normal maximum-transmission-unit for UDP. Namespaces are capped at 64 bytes and values can be up to 1419. After that they’re cut off.
Same expiry
All namespaces and entries in the entire server have the same expire time (in seconds). It shouldn’t be too difficult to run multiple draculas on other ports f you have different expiry needs.
HA
The approach to high-availability assumes short-lived expiry of entries. A pool of dracula servers can replicate to one another, and dracula clients track health of pool members, automatically handling failover. Any client can read from any server, but in the case of network partitioning, consistency won’t be perfect.
Retries
Messages that fail or timeout are not retried by the dracula client right now. There’s nothing stopping the application level from handling this. It may be added as an option later.
Garbage
While we have not yet experienced issues with dracula’s garbage collection, it’s worth noting that it exists. A subset of entries are crawled and expired on a schedule. On “count” commands, old entries are expired. The entire store is typically not locked, but it’s likely you would see a little slowdown when counting entires in very large namespaces, or when there are a lot of old entires to cleanup, while GC is running. In our testing it’s on the order of single digit miliseconds, but this can be expected to grow linearly with size.
Unknown scale
We’re working with low-tens-of-thousands entries per namespace, maximum. Above that, we’re unsure how it will perform.
Language support
Upon release, dracula has a reference client implementation in Golang. Node.js support is on our radar, but not finished. Please open an issue in the dracula repo to request support for a specific language. We’d be thrilled to receive links to community written drivers as well.
What’s next?
Hopefully you enjoyed learning a little bit about dracula and are ready to give it a try. Head over to Github https://github.com/mailsac/dracula where added examples of using the server, client library, and CLI.
Finally, Mailsac would love your feedback. Open a Github issue or head to forum.mailsac.com. If you’d like to see additional library languages supported, let us know.
Mailsac has added a new spamminess indicator in the API.
New messages will have a spam property that’s a score between 0.0 and 1.0. 1.0 indicates a high likelihood of spam. The system will get smarter over time.
The main component of spam detection is a time tested approach called Naive Bayes Classifier. The core of the code is open source at github.com/mailsac/spam-classifier, though a little special sauce is applied, too. This classifier library is ready to use and includes a simple API server and a terminal training tool.
In the works are additional spam classification projects using three different deep learning techniques: random forest, a long short term neural network, and a combination recurrent network + liquid state machine with spike dependent plasticity. The goal is to open source the useful pieces of the coming spam classifiers.